
Quando alguém fala sobre como ter resiliência na AWS, pode perceber que a conversa será direcionada a projetar um ambiente failover Multi-AZ na AWS. E isso faz sentido. Tanto que a própria AWS recomenda distribuir a aplicação em várias zonas de disponibilidade (AZ) para aumentar a tolerância a falhas. O problema é quando paramos o desenvolvimento da arquitetura nesse ponto e não continuamos em um plano de failover multi-região na AWS.
Se a sua aplicação pode aceitar uma interrupção regional rara, mas possível, talvez uma arquitetura em uma única região seja suficiente. Mas, se o negócio precisa continuar operando mesmo com uma falha regional, então precisamos pensar em ter um failover multi-região.
Sumário
O que muda para um failover multi-região?
Primeiro, é importante deixar claro que projetar failover multi-região não significa copiar recursos para uma outra região. Na prática, você precisa desenhar como o tráfego será redirecionado, como os dados serão replicados e qual tempo de recuperação o negócio aceita.
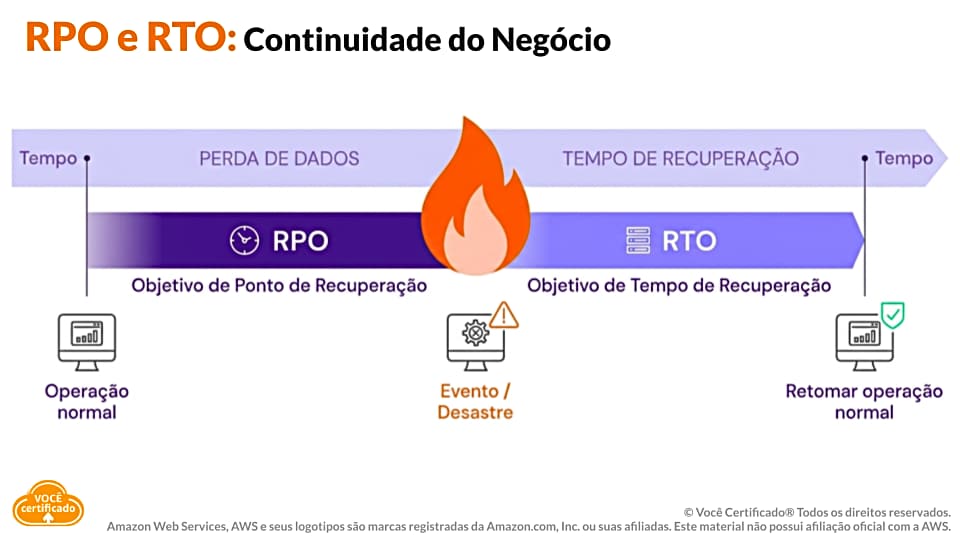
E, segundo, a decisão da sua arquitetura tem de ser ponderada em quanto tempo será sua recuperação (RTO) e qual será a perda aceitável (RPO).
Na camada de entrada, as opções mais comuns envolvem Amazon Route 53, com health checks e política de failover, e AWS Global Accelerator, que verifica a saúde dos endpoints e envia tráfego apenas para endpoints saudáveis.
Se o seu projeto puder utilizar o Amazon CloudFront, haverá ganhos significativos na entrega do conteúdo, por meio do cache na borda disponível e failover entre origens. Mas aqui existe um detalhe importante de mencionar. O failover de origem do CloudFront vale apenas para requisições GET, HEAD e OPTIONS. Para métodos como POST e PUT, ele não resolve sozinho o cenário de continuidade da aplicação.
Esse ponto é importante porque mostra que failover multi-região não é simplesmente “ligar” um serviço de borda e esperar que tudo esteja resolvido. O roteamento ajuda, mas ele é apenas uma parte do desenho da sua arquitetura. A recuperação real depende da combinação entre tráfego, computação, automação e principalmente dados.
Quais são as estratégias disponíveis?
Na AWS, as estratégias de recuperação de desastres podem ser agrupadas em quatro abordagens principais, que vão desde opções mais simples e econômicas, como backup, até arquiteturas mais complexas com múltiplas regiões ativas. A escolha entre elas depende principalmente do RTO, do RPO, do orçamento disponível e do nível de complexidade operacional que a empresa está disposta a assumir.
A AWS classifica essas abordagens como backup e restauração, luz piloto, standby aquecido e multi-site ativo/ativo. E para facilitar o seu entendimento, preparei uma tabela com suas características:
| ESTRATÉGIA | CUSTO | TEMPO RECUPERAÇÃO | CARACTERÍSTICA PRINCIPAL | CENÁRIO |
|---|---|---|---|---|
| Backup e restauração | Baixo | Lento | Os dados ficam protegidos em backup e o ambiente precisa ser restaurado ou reimplantado | Quando o negócio tolera maior indisponibilidade |
| Luz piloto | Baixo a médio | Mais rápida que backup e restauração | Os dados e a base crítica já estão prontos na região secundária | Quando eu quero reduzir RTO sem manter tudo ativo |
| Standby aquecido | Médio | Rápida | Uma versão reduzida da aplicação já fica em execução | Quando eu preciso de uma recuperação previsível |
| Multi-site ativo/ativo | Alto | Muito rápida | Duas ou mais regiões atendem produção ao mesmo tempo | Quando a indisponibilidade regional tem alto impacto |
Em backup e restauração, estamos priorizando os custos. Os dados são preservados e a infraestrutura pode ser reimplantada a partir de automação, como AWS CloudFormation ou AWS CDK. Em compensação, o tempo de recuperação tende a ser maior, porque a aplicação precisa ser reconstruída ou restaurada para voltar a operar.
No luz piloto, mantemos o que é essencial preparado na região de recuperação, principalmente os dados e componentes básicos. Já as outras partes da aplicação ainda precisam ser ativadas quando o failover ocorre. É uma abordagem que reduz custo em relação a ambientes sempre ativos, mas ainda exige etapas operacionais na recuperação.
No standby aquecido, mantemos uma versão reduzida da aplicação em execução em uma região secundária. Isso permite um failover rápido e previsível, porque uma parte importante do ambiente já está operacional. Em comparação com a luz piloto, o custo aumenta, mas o processo de recuperação tende a ser mais simples, já que a infraestrutura crítica não precisa ser criada do zero no momento do desastre.
No multi-site ativo/ativo, duas ou mais regiões atendem o tráfego simultaneamente. Essa abordagem entrega o nível mais alto de continuidade, mas também cobra mais em custo, observabilidade, automação e no desenho da arquitetura dos dados. Na minha opinião, muitas equipes tentam pular cedo demais para esse modelo, quando uma estratégia intermediária, como a luz piloto, já atenderia muito bem.
E em projetos em que já atuei e que não eram críticos, a estratégia de backup e restauração conseguia me atender muito bem. Também recomendo a automação com o AWS Backup e testem se a restauração funciona.
Por que a camada de dados é a parte crítica?
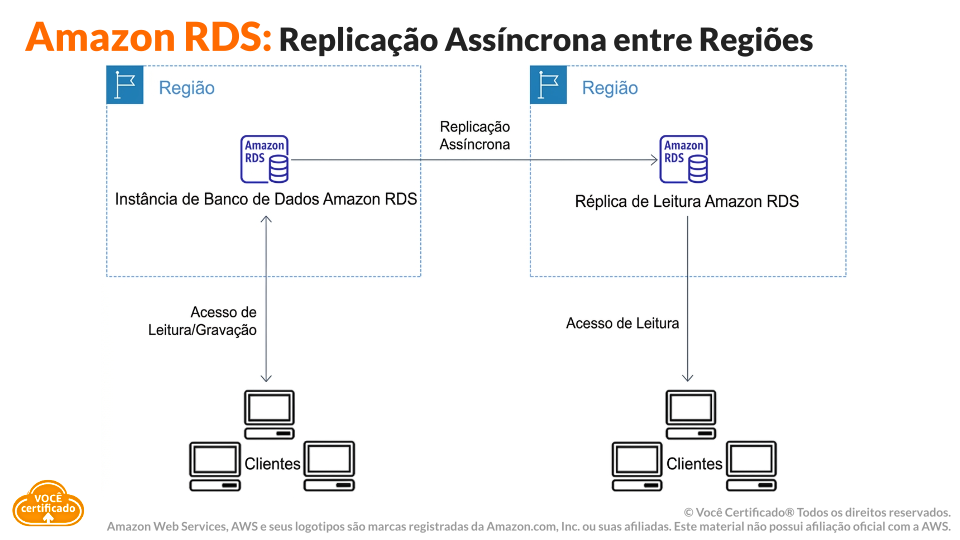
Sejamos sinceros. A computação pode ser recriada com relativa facilidade. Agora os dados, esses não. É por isso que a AWS trata banco de dados, backup e failover como as partes centrais da resiliência das aplicações.
Os cinco erros mais comuns
- Achar que Multi-AZ substitui multi-região. Não substitui. O multi-AZ aumenta a resiliência regional, mas não atende sozinho a um cenário de indisponibilidade da região inteira.
- Olhar primeiro para o roteamento e depois para os dados. O caminho correto costuma ser o contrário. Se os dados não estiverem disponíveis, o failover não entregará continuidade na recuperação.
- Superestimar o que o CloudFront resolve tudo sozinho. O failover de origem ajuda, mas não cobre todos os métodos HTTP e não substitui uma estratégia completa de recuperação.
- Escolher a arquitetura mais complexa, antes de definir o requisito do negócio. Nem toda aplicação precisa de multi-site ativo/ativo. Muitas precisam apenas de uma estratégia coerente, testável e compatível com o custo que cabe no bolso.
- Não testar a recuperação. Uma estratégia de recuperação só ganha valor quando é testada e validada. Dizer que tem uma recuperação de desastres na arquitetura sem testar não é garantia de recuperação.
Agora que você entendeu o que costuma dar errado, a pergunta que podemos fazer é: como eu posso começar do jeito certo?
O que eu já fiz que deu certo
- Tenha uma arquitetura com Multi-AZ.
- Defina o RTO e RPO de forma realista com o projeto.
- Escolha uma estratégia de recuperação e simule um desastre em um ambiente controlado.
- Automatize os backups e volte ao passo 2 dentro de alguns dias.
Na prática, eu não começaria com multi-site ativo/ativo, a não ser que seja um requisito do cliente ou do projeto. Em muitos cenários, o backup e restauração e a luz piloto já entregam o que você precisa e com baixo custo.
Também vale lembrar que projetar um ambiente failover multi-região não é um exercício de continuidade. Mas sim uma excelente oportunidade para amadurecer a sua visão de arquitetura na AWS e entregar um projeto robusto para o seu cliente, porque vai lhe obrigar a conectar rede, fazer o roteamento, pensar nos dados, ativar automação e testar a operação.
Se você está começando a estudar AWS, entender esses fundamentos ajuda a enxergar por que a nuvem não é apenas um conjunto de serviços, mas um conjunto de decisões de arquitetura.
